용어정리
리스트 컴프리핸션 : 리스트 안에 식, for 반복문, if 조건문 등을 지정하여 리스트를 생성하는 것
메서드 체이닝 : method-chaining으로 메소드를 줄줄이 연결한다는 뜻으로 사용된다.
본문정리
Unit 22.
append : 요소 하나를 추가하는 메서드이다.
extend : 리스트를 연결하여 확장하는 메서드이다.
insert : 특정 인덱스에 요소를 추가하는 메서드이다.
append에 리스트를 넣으면 리스트안에 리스트가 들어가는 것이다.
>>> a = [10, 20, 30]
>>> a.append([500, 600])
>>> a
[10, 20, 30, [500, 600]]
>>> len(a)
4위의 문제로 extend를 사용하는 것이다.
>>> a = [10, 20, 30]
>>> a.extend([500, 600])
>>> a
[10, 20, 30, 500, 600]
>>> len(a)
5하지만 append와 extend는 모두 끝에 추가하는 것 밖에 되지 않는다. 이 때문에 insert를 사용하는 것이다.
>>> a = [10, 20, 30]
>>> a.insert(2, 500)
>>> a
[10, 20, 500, 30]
>>> len(a)
4하지만 insert 또한 리스트에 리스트를 넣는 것만 가능하다. 리스트 중간에 요소를 넣기 위해선 슬라이스를 이용해야 한다.
여태 추가하는 것을 배웠고 이제는 요소 삭제에 대해 다뤄보려한다.
pop : 특정 인덱스의 요소를 삭제하는 메소드이다.
remove : 특정 값을 찾아 삭제하는 메소드이다.
pop은 이하와 같이 사용한다.
>>> a = [10, 20, 30]
>>> a.pop(1)
20
>>> a
[10, 30]
pop()으로 적으면 마지막 요소가 삭제된다. pop이 아닌 del a[1]을 통해 삭제를 할 수도 있다.
remove는 다음과 같이 사용한다,
>>> a = [10, 20, 30, 20]
>>> a.remove(20)
>>> a
[10, 30, 20]여기서 삭제하고 싶은 요소 중 첫번째 값만 삭제 됨을 알 수 있다.
이상 요소를 추가/삭제하는 것을 배웠으며 이제는 부가 기능을 배우려한다.
index : 리스트에서 특정 값의 인덱스를 구한다.
>>> a = [10, 20, 30, 15, 20, 40]
>>> a.index(20)
1이도 마찬가지로 찾고 싶은 값의 처음 인덱스를 추출한다.
count : 리스트에서 특정 값의 개수를 구한다.
>>> a = [10, 20, 30, 15, 20, 40]
>>> a.count(20)
2reverse : 리스트에서 요소의 순서를 반대로 뒤집는다.
>>> a = [10, 20, 30, 15, 20, 40]
>>> a.reverse()
>>> a
[40, 20, 15, 30, 20, 10]sort : 리스트의 요소를 정렬한다. ()안에 reverse=false면 오름차순, reverse=true면 내림차순이다.
sorted라는 메소드도 있는데 이는 sort와 다르다. sort는 원래 리시트를 바꾸는 반면 sorted는 새로운 리스트를 생성한다.
>>> a = [10, 20, 30, 15, 20, 40]
>>> a.sort()
>>> a
[10, 15, 20, 20, 30, 40]clear : 리스트의 모든 요소를 삭제한다. 물론 del a[:]을 통해서도 가능하다.
>>> a = [10, 20, 30]
>>> a.clear()
>>> a
[]
자료를 추가로 읽어보면 슬라이스를 잘 쓰는게 중요할 듯하다. 이 부분을 조금 더 익숙하게 만들어야겠다.
할당과 복사는 다른 개념이다. 할당은 같은 객체를 가리키는 것이고 복사는 다른 객체를 가리키는 것이다.
할당은 b=a이고 복사는 a = b.copy()이다.
인데스와 요소를 함께 출력하기 위해선 enumerate를 이용하면 된다.
>>> a = [38, 21, 53, 62, 19]
>>> for index, value in enumerate(a):
... print(index, value)
...
0 38
1 21
2 53
3 62
4 19>>> for index, value in enumerate(a, start=1):
... print(index, value)
...
1 38
2 21
3 53
4 62
5 19이는 인덱스를 1부터 시작하라는 의미이다.
최고,최저 값 구하는 방식은 for, while을 이용해도 되지만 파이썬은 max, min을 사용가능하다
합 또한 sum을 이용가능하다.
리스트 표현식은 다음과 같다.
>>> a = [i for i in range(10)] # 0부터 9까지 숫자를 생성하여 리스트 생성
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> b = list(i for i in range(10)) # 0부터 9까지 숫자를 생성하여 리스트 생성
>>> b
[0, 1, 2, 3, 4, 5, 6, 7, 8, 조건식을 넣어도 사용가능하다.
>>> a = [i for i in range(10) if i % 2 == 0] # 0~9 숫자 중 2의 배수인 숫자(짝수)로 리스트 생성
>>> a
[0, 2, 4, 6, 8]위의 것들을 응용하면 다음과 같다. 이때 처리 순서는 뒤부터 앞이다.( 나는 그렇게 생각하지 않는게 i에 2를 대입한 이후 j에 1~9를 대입하는 것 아닌가?)
>>> a = [i * j for j in range(2, 10) for i in range(1, 10)]
>>> a
[2, 4, 6, 8, 10, 12, 14, 16, 18, 3, 6, 9, 12, 15, ~~~]
리스트의 항목은 map을 이용하여 요소를 변환할 수 있다. 이때 map에는 int 말고도 str 등을 이용할 수 있다.
>>> a = [1.2, 2.5, 3.7, 4.6]
>>> a = list(map(int, a))
>>> a
[1, 2, 3, 4]
튜플은 요소의 정보만 구할 수 있다.(index, count 정도만 사용가능)
Unit 23.
2차원 리스트를 만드는 방식을 설명한다.
>>> a = [[10, 20], [30, 40], [50, 60]]
>>> a[0] [0] # 세로 인덱스 0, 가로 인덱스 0인 요소 출력
10
>>> a[1][1] # 세로 인덱스 1, 가로 인덱스 1인 요소 출력
40
>>> a[2][1] # 세로 인덱스 2, 가로 인덱스 0인 요소 출력
60
>>> a[0][1] = 1000 # 세로 인덱스 0, 가로 인덱스 1인 요소에 값 할당
>>> a[0][1]
1000출력하는 방식에는 여러 가지 방식이 있다. 다양한 방식이 있지만 핵심은 요소를 하나 받는다!라는 것이다. 밑의 예를 살펴보자
for i in a: # a에서 안쪽 리스트를 꺼냄
for j in i: # 안쪽 리스트에서 요소를 하나씩 꺼냄
print(j, end=' ')
print()이 문장의 경우 i가 a의 요소 중 하나를 받는다. 그 후 j가 i를 구성하는 요소 2개 중 하나를 받는다.
이제부터는 2차원 리스트만드는 방식을 배운다.
a = [] # 빈 리스트 생성
for i in range(3):
line = [] # 안쪽 리스트로 사용할 빈 리스트 생성
for j in range(2):
line.append(0) # 안쪽 리스트에 0 추가
a.append(line) # 전체 리스트에 안쪽 리스트를 추가실행 결과는 [ [0,0], [0,0], [0,0] ]이 나온다.(여기서 객체지향 언어의 특징이 들어나는 것 같다.)
>>> a = [[0 for j in range(2)] for i in range(3)]
>>> a
[[0, 0], [0, 0], [0, 0]]이렇게도 적는다는데 많이 어색하게 느껴진다. 정렬방식 또한 있는데 아예 이해가 안돼서 나중에 적으려고 한다.
2차원의 경우 복사를 하기 위해선 copy.deepcopy를 해야한다. 일반 copy로 하면 할당이된다.
Unit 24.
문자열에 대해 다루는 유닛이다.
replace('바꿀 문자열', '새 문자열') : 말그대로 문자열 안의 문자열을 다른 문자열로 바꾼다.
문자 또한 바꿀 수 있는데 str.maketrans('바꿀문자','새문자') →translate(이전단계 가르키는 레퍼런스)순으로 작성한다 이하는 예이다.
>>> table = str.maketrans('aeiou', '12345')
>>> 'apple'.translate(table)
'1ppl2'split과 join은 상응하는 개념이다. join은 문자열을 리스트로 만든다. 이하는 예이다.
>>> ' '.join(['apple', 'pear', 'grape', 'pineapple', 'orange'])
'apple pear grape pineapple orange'
'문자열'.upper() or .lower()는 대소문자로 만들어준다.
'문자열'.lstrip() or .rstrip() or strip()은 왼쪽, 오른쪽, 양쪽 공백을 없애준다. 이를 이용해 ()안에 ('삭제하고 싶은 문자')를 입력하면 마찬가지로 왼쪽, 오른쪽, 양쪽의 특정 문자들을 없애준다.
'문자열'.ljust(특정길이) or rjust(특정길이) or center(특정길이)는 해당문자열을 특정길이에 왼쪽, 오른쪽, 중간에 넣는 것이다. 남은 길이는 공백으로 둔다. 가운데 둘 때 홀수 길이가 남으면 왼쪽에 한칸을 더 둔다.
zfill(특정길이) : zero fill과 같은 의미로 남은 길이를 0으로 앞을 채운다.
find('문자열') : 문자열을 찾고 인덱스로 표현한다. 없으면 -1을 출력한다. (rfind는 오른쪽부터 찾는다)
index('문자열') : 위와 동일하지만 없으면 에러를 일으킨다.(rindex도 있다)
count('문자열') : 특정 문자열이 몇번 나오는지 센다.
서식지정자를 이용해 코딩하는 법을 배워보자.
>>> 'I am %s.' % 'james'
'I am james.'>>> '%f' % 2.3
'2.300000'>>> 'Today is %d %s.' % (3, 'April')
'Today is 3 April.소숫점 이하의 자리는 %.?f처럼 작성하면 되며 특정 길이는 %특정길이s로 설정하면 된다. 왼쪽에 붙이는 것은 %-특정길이s로 선언하면 된다.
또한 format을 이용하는 방법도 있다. 이하는 쓰는 방식이다.
>>> 'Hello, {0} {2} {1}'.format('Python', 'Script', 3.6)
'Hello, Python 3.6 Script'만약 {}처럼 안에 인덱스가 없다면 순서대로 들어간다.(위의 예시면 Python → Script → 3.6 순)
또한 인덱스가 아닌 이름으로 넣을 수도 있다.
>>> 'Hello, {language} {version}'.format(language='Python', version=3.6)
'Hello, Python 3.6'이하도 이름으로 넣었지만 여기선 변수를 넣는 것으로 앞에 formatting을 뜻하는 f를 붙인다.
>>> language = 'Python'
>>> version = 3.6
>>> f'Hello, {language} {version}'
'Hello, Python 3.6'문자열을 정렬할건데 여기서 중요한건 <과 >이 크기 비교가 아니다.
>>> '{0:<10}'.format('python')
'python '>>> '{0:>10}'.format('python')
' python'
위의 내용들을 종합하여 다음과 같이 만들 수도 있다.
>>> '%08.2f' % 3.6
'00003.60'
>>> '{0:08.2f}'.format(150.37)
'00150.37'여기서 8은 총 칸수를 의미한다.
>>> '{0: >10}'.format(15) # 남는 공간을 공백으로 채움
' 15'
>>> '{0:>10}'.format(15) # 채우기 부분을 생략하면 공백이 들어감
' 15'
>>> '{0:x>10}'.format(15) # 남는 공간을 문자 x로 채움
'xxxxxxxx15'
Unit 25.
딕셔너리를 이용하는 방식에 대해 설명하는 유닛이다.
키-값 쌍을 추가하기 위해서 사용되는 방식에는 2가지가 있다.
먼저 setdefault가 있다. 키만 입력하게되면 값에는 None이 들어간다. 이하는 사용방식이다.
>>> x.setdefault('f', 100)
100
>>> x
{'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': None, 'f': 100}update는 값을 변경하는데 사용하나 수정 키가 없으면 키와 값을 추가한다. 이하는 사용방식이다.
>>> x.update(a=900, f=60)
>>> x
{'a': 900, 'b': 20, 'c': 30, 'd': 40, 'e': 50, 'f': 60}위는 zip을 이용해도 된다.
>>> y.update(zip([1, 2], ['one', 'two']))
>>> y
{1: 'one', 2: 'two', 3: 'THREE', 4: 'FOUR'}
삭제하는 방식으론 pop이 있다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x.pop('a')
10
>>> x
{'b': 20, 'c': 30, 'd': 40}만약 pop('키값','기본값')으로 입력한다면 키값이 없을 경우 기본값을 반환한다.(기본값을 입력안하면 에러가 발생한다.) del x['a']처럼 삭제해도 된다.
popitem()은 마지막 키-값을 튜플형식으로 반환하며 삭제한다.
키의 값을 가져오는 방식으론 get이 있다. 활동 방식은 pop과 동일하다.
딕셔너리의 키-값, 키, 값을 가져오는 방식의 메서드는 item(),keys(), values()이다.
리스트와 튜플로 딕셔너리를 만드는 메서드는 dict.fromkeys()이다.
>>> keys = ['a', 'b', 'c', 'd']
>>> y = dict.fromkeys(keys, 100)
>>> y
{'a': 100, 'b': 100, 'c': 100, 'd': 100}여기서 기본값을 입력하지 않으면 None이 들어간다.
키와 값을 for문으로 가져오는 방식은 다음과 같다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> for key, value in x.items():
... print(key, value)
...
a 10
b 20
c 30
d 40여기서 item() 대신 keys(), values()를 이용가능하다.
표현식에 대한 설명이다.
>>> keys = ['a', 'b', 'c', 'd']
>>> x = {key: value for key, value in dict.fromkeys(keys).items()}
>>> x
{'a': None, 'b': None, 'c': None, 'd': None}
for문으로 키-값쌍을 삭제가 불가능하다. 때문에 표현식에서 if조건문을 사용해야 한다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x = {key: value for key, value in x.items() if value != 20}
>>> x
{'a': 10, 'c': 30, 'd': 40}딕셔너리를 중첩해서 사용할 수도 있다.
terrestrial_planet = {
'Mercury': {
'mean_radius': 2439.7,
'mass': 3.3022E+23,
'orbital_period': 87.969
},
'Venus': {
'mean_radius': 6051.8,
'mass': 4.8676E+24,
'orbital_period': 224.70069,
},
'Earth': {
'mean_radius': 6371.0,
'mass': 5.97219E+24,
'orbital_period': 365.25641,
},
'Mars': {
'mean_radius': 3389.5,
'mass': 6.4185E+23,
'orbital_period': 686.9600,
}
}
print(terrestrial_planet['Venus']['mean_radius']) # 6051.8
여기서도 할당과 복사의 개념이 나오는데 마찬가지로 일반적인 딕셔너리는 copy를 중첩 딕셔너리에는 deepcopy를 적용해야 복사가 된다.
Unit 26.
세트에 대한 설명을 다루는 유닛이다.
세트의 선언은 다음과 같다.
>>> fruits = {'strawberry', 'grape', 'orange', 'pineapple', 'cherry'}
>>> fruits
{'pineapple', 'orange', 'grape', 'strawberry', 'cherry'}딕셔너리와 차이는 키-값이 묶여있지 않다는 것이다. 또한 세트를 이루는 요소가 동일하다면 하나의 요소만 들어간다. 가장 큰 특징은 특정 요소만 출력할 수 없다는 것이다.([]여기서 인덱스 사용이 불가능하단 의미이다.)
특정 요소가 있는지 확인하는 방법은 in이다.
>>> fruits = {'strawberry', 'grape', 'orange', 'pineapple', 'cherry'}
>>> 'orange' in fruits
True
>>> 'peach' in fruits
False선언하는 방법은 이하와 같다.
>>> a = set('apple') # 유일한 문자만 세트로 만듦
>>> a
{'e', 'l', 'a', 'p'}주의해야 할 점은 두가지 이다. 겹치는 것은 한번만 들어간다는 것과 선언시()를 사용한다는 것이다.{}를 사용하는 것은 dict이다.
또한 요소 추가·삭제를 불가능하게하는 프로즌세트도 있다. 중첩사용시 프로즌세트 안에는 프로즌세트만 가능하고 일반 세트는 불가하능하다.
>>> a = frozenset(range(10))
>>> a
frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
세트는 합집합, 교집합, 차집합과 XOR에 대한 계산이 가능하다.
>>> a = {1, 2, 3, 4}
>>> b = {3, 4, 5, 6}
>>> a | b
{1, 2, 3, 4, 5, 6}
>>> set.union(a, b)
{1, 2, 3, 4, 5, 6}>>> a & b
{3, 4}
>>> set.intersection(a, b)
{3, 4}>>> a - b
{1, 2}
>>> set.difference(a, b)
{1, 2}위를 이용하여 연산이 가능하다. 이하는 예시이다.
>>> a = {1, 2, 3, 4}
>>> a |= {5}
>>> a
{1, 2, 3, 4, 5}
>>> a = {1, 2, 3, 4}
>>> a.update({5})
>>> a
{1, 2, 3, 4, 5}>>> a = {1, 2, 3, 4}
>>> a &= {0, 1, 2, 3, 4}
>>> a
{1, 2, 3, 4}
>>> a = {1, 2, 3, 4}
>>> a.intersection_update({0, 1, 2, 3, 4})
>>> a
{1, 2, 3, 4}>>> a = {1, 2, 3, 4}
>>> a -= {3}
>>> a
{1, 2, 4}
>>> a = {1, 2, 3, 4}
>>> a.difference_update({3})
>>> a
{1, 2, 4}>>> a = {1, 2, 3, 4}
>>> a ^= {3, 4, 5, 6}
>>> a
{1, 2, 5, 6}
>>> a = {1, 2, 3, 4}
>>> a.symmetric_difference_update({3, 4, 5, 6})
>>> a
{1, 2, 5, 6}세트는 집합이라 하였으므로 부분 집합, 상위 집합인지에 대해서도 확인할 수 있다.
>>> a = {1, 2, 3, 4}
>>> a <= {1, 2, 3, 4}
True
>>> a.issubset({1, 2, 3, 4, 5})
True>>> a = {1, 2, 3, 4}
>>> a >= {1, 2, 3, 4}
True
>>> a.issuperset({1, 2, 3, 4})
True그 밖에도 세트가 같은지 다른지(== !=) 겹치는지 확인 가능하다.
>>> a = {1, 2, 3, 4}
>>> a.isdisjoint({5, 6, 7, 8}) # 겹치는 요소가 없음
True
>>> a.isdisjoint({3, 4, 5, 6}) # a와 3, 4가 겹침
False세트에 요소를 추가, 삭제할 수 있다.
>>> a = {1, 2, 3, 4}
>>> a.add(5)
>>> a
{1, 2, 3, 4, 5}>>> a.remove(3)
>>> a
{1, 2, 4, 5}>>> a.remove(3)
>>> a
{1, 2, 4, 5}remove와 discard의 차이는 앞의 경우 해당 값이 없으면 오류가 발생한다는 것이다.
pop은 세트의 제일 앞에 있는 값을 반환한다. 값이 없다면 에러가 발생한다. 그밖에 len,clear는 상식과 같다. 또한 copy가 가능하다.
표현식도 앞에서 언급한 것이랑 비슷한 느낌이다.
>>> a = {i for i in 'pineapple' if i not in 'apl'}
>>> a
{'e', 'i', 'n'}
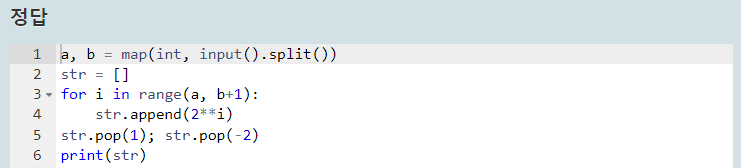
본문제











'python > 자습' 카테고리의 다른 글
| Unit 16 - 21(파이썬 코딩 도장) (0) | 2022.10.30 |
|---|---|
| Unit 13 - 15(파이썬 코딩 도장) (0) | 2022.10.29 |
| Unit 8 - 12(파이썬 코딩 도장) (0) | 2022.10.29 |
| Unit 5 - 7(파이썬 코딩 도장) (0) | 2022.10.29 |
| Unit 1 - 4(파이썬 코딩 도장) (0) | 2022.10.29 |




댓글